
How AIs Fail at Reading Clocks
and Why That’s Important

Draft v3.1 for Fuego, 2026-05-08 Co-authored with The Salon (Terry, Opus 4.7)
You may have seen my post about clocks. It’s my latest obsession. Not because I care about clocks specifically but because I’m interested in how AI systems perceive the world. It’s the same reason I did experiments on how they perceive colors.
Just like those color studies, the most useful information came from evaluating how those systems fail. It turns out, when it comes to AIs and clocks, there are a lot of failures to study.
Why are failure modes important?
Think about it.
People are talking about using AIs to replace humans in many applications. It’s logical. AIs seem to do a really good job. But a lot of what we (humans) do is visual. We navigate the world. We identify faces. We read dials and gauges and clocks. What if someone decides to use an AI to read a gauge in order to automate something? And what happens when the AI reports it sees ‘3’ when the gauge actually reads ‘9’. That wouldn’t be very good, would it? In fact, you could end up blowing things up.
No one would be that stupid, right? RIGHT?
So join me on what I thought would be a quick test of AIs reading clocks. Several thousand trials later I think I distilled down the error modes. That’s the good news. The bad news is, unless you run these types of validation experiments, you’re not going to know whether your particular AI is any good at something because AI models behave differently. I started with trials across Anthropic, OpenAI and Google. But that took too long and got expensive quickly. Ultimately I settled on Anthropic’s Sonnet and Opus models and found that while performance varies considerably on tasks, the fundamental types of errors were the same.
How AIs Fail at Reading Gauges
Vision-language models fail at reading analog clocks for three separable reasons, and the same patterns will hit any task where you point a needle at a labeled scale. Speedometers. Compasses. Pressure gauges. Anywhere a line points at a labeled position, the failure modes we documented likely come into play.
We found three generalizable patterns:
Perceptual extrapolation. When a pointer’s tip is at the labels, these AI models read nearly perfectly. But when the tip doesn’t go all the way to the label, accuracy collapses. This is what makes the short hour hand on an analog clock less accurate to read than the long minute hand. The hour hand’s tip sits well inside the numeral ring; the model has to extrapolate its direction outward, and that extrapolation fails far too often.
Hand-role identification. Two-hand clocks force the model to decide which hand is which. With clear length differences, it usually gets it right. Reduce the disparity and role-swap errors emerge. Add explicit color disambiguation (red for hour, blue for minute) and they vanish. The mechanism is separable from perception and depends on visual cues, not angle reading.
Position-to-hour conversion. When the hour hand is more than two-thirds of the way to the next numeral, models often default to “nearest numeral” instead of “earlier numeral.” 7:45 becomes 8:45. 11:40 becomes 12:40. This persists even when role identification is clearly specified to the model and the hand is long enough to reach the labels. The model can explain the convention verbally so it seems like it understands. But when it comes to actually reading the clock, it doesn’t apply the verbal information to the act of reading the time.
The clock reading task fails because real clocks combine all three. Short hour hand. Two hands to tell apart. Hour hand near a numeral most of the time. Each pattern individually is testable, falsifiable, and architecturally distinct.
My tests started with what was supposed to be a quick afternoon experiment. Run a small follow-up to my prior clock reading study. Thousands of API calls later, the picture sharpened through a series of experiments that revealed new details that often invalidated previous hypotheses.
Round 1
We had a rough taxonomy of clock-reading failures. Forward-shift: the hour reads as past the correct numeral. Hand-swap: the model can’t reliably tell hour from minute. And a few others.
I also wondered if we could teach a model by training it about the errors. We ran a Sonnet 4.6 student through a simple clock reading exercise, turn-by-turn, see if dialogic correction can fix the failures. It couldn’t.
Round 1 established a baseline. Sonnet got four out of eight first-attempts correct. Same failure modes we’d seen before. 7:45 read as 8:45. 2:35 read as 7:15. Stuck on 5:50 after fourteen turns of training. Same errors we’d seen in previous tests but we were starting to understand the patterns.
For Round 2 we stacked three interventions. Enable thinking mode (so the model could spend a budget on internal reasoning). Give it a “take your time, check your work” system prompt. Add a heads-up about the forward-shift failure mode. Tell it what to watch for, the way you’d warn a student.
The score got worse. Three out of seven correct. Cardinals broke. 3:00 read as 12:15.
Telling the model about a known bias triggered an over-correction in the opposite direction. We told it “the hour hand can read as past the upcoming numeral instead of the current one.” It started reading the hour hand as past the prior numeral instead. Instead of moving perception closer to truth, it just shifted which side of truth perception landed on. You got to give it partial credit for effort...
Naming a bias to a model the way you’d name it to a student doesn’t fix the bias. It triggers an opposite-direction over-correction. The pattern is going to come back.
Visual style dominates
In order to simplify the experiments to isolate failures, we ran an hour-hand-only experiment. Render a clock with no minute hand, just the hour-hand at various angles, ask the model to estimate the time. Then a converse: minute-hand only, ask the AI to read where it was pointing. These should be simple dial reading analogs. Maybe not so simple.
We found that the AI read the minute-hand far more accurately than the hour-hand. Much more accurately. Weird. So we swapped the style of the hands to see if it was something about the visual style that caused the difference. Bingo!
Hour-hand angles drawn with the long thin visual of the minute-hand: 100 percent within fifteen degrees of truth. Minute-hand angles drawn with the short thick visual of an hour-hand: 42 percent within fifteen degrees.
Same angles. Same prompt. Different hand visual. Four-times accuracy difference.
The hand style was driving the gap, not the angle and not the role of the hand on the clock. We also tested whether the numerals on the clock face were attracting bad readings. So we removed the numerals entirely, kept just the tick marks. No improvement. The numerals weren’t attracting the readings in this case.
What looked like the big reveal
By this point we had something like five different possible “mechanisms”. The lower-half of the dial seems to fail. Cardinal numerals seem to attract in certain cases. Visual style matters. Training data matters (10:10 reads correctly because it’s the standard watchmaker pose). The paper was becoming a list of unrelated patterns.
We thought about extrapolation errors. Humans do it visually. It’s natural to follow a line to see where it points. But it’s not obvious that an AI can do the same thing. So we tested it.
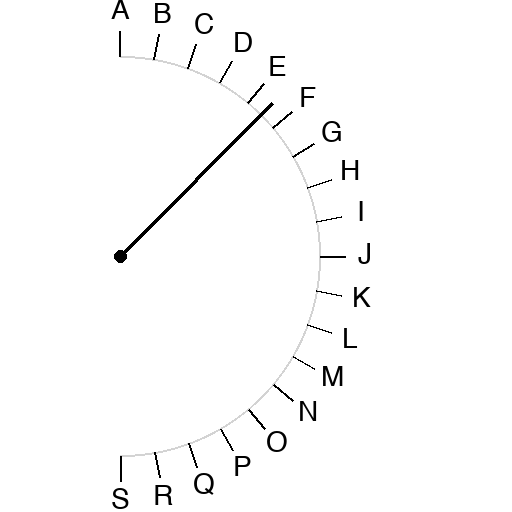
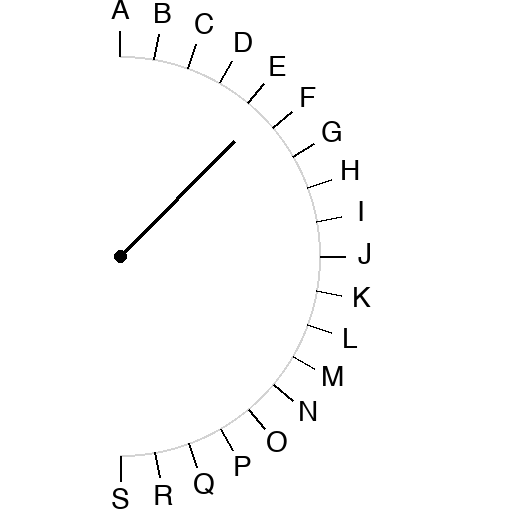
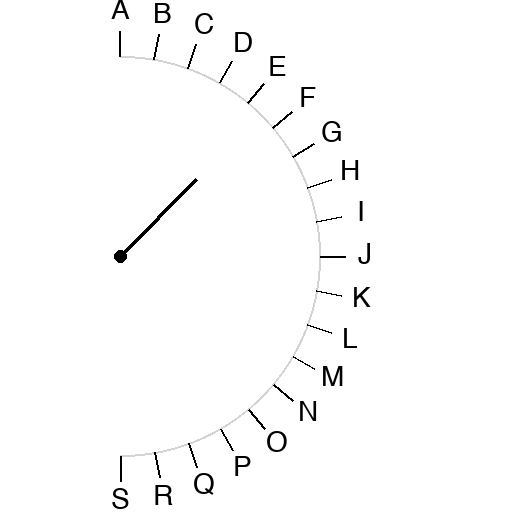
Half-circle scale. Letters A through S at ten-degree increments. A pivot dot. A pointer line from the pivot at some angle. Three line-length conditions: full (tip reaches the letter ring), three-quarter, half. Ask the model which letter the line points at.
We ran 1110 trials. Thirty-seven angles, three lengths, five trials each, two models.
Opus full-length: 185 out of 185 correct. Maximum angular error: five degrees.
Opus three-quarter: 51 percent correct. Maximum error 165 degrees.
Opus half-length: 53 percent correct. Maximum error 180 degrees, a complete opposite-end flip.
The slight inversion between Opus 3/4 (51 percent) and Opus 1/2 (53 percent) is within trial-to-trial noise; both are essentially the same floor at around half. The interesting story is the dropoff from full-length to anything-shorter.
Sonnet full-length: 94 percent correct.
Sonnet three-quarter: 47 percent.
Sonnet half-length: 27 percent.
Same angles. Same model. Same prompt. Only the pointer length changes. Accuracy collapses by 40 to 67 percentage points.
I wrote it up. All five “mechanisms” we’d been tracking collapse into this. The cardinal attractors? Biased extrapolation defaulting to strong visual axes. The visual-style effect? Long thin hand has its tip near the numeral ring; short thick hand’s tip is interior. The training-data priors? When the stimulus matches a memorized pose, pattern-matching wins over extrapolation.
One mechanism. The perception of where a line points when its tip falls short of the labels.
Then we ran the validation experiment.
What looked like a unified mechanism wasn’t
The half-circle finding made a falsifiable prediction. A real clock with both hands drawn long, tips reaching the numeral ring, should read accurately even on the stimuli that fail today. We tested it. Same ten stimuli as the dialogic teaching set, both hands drawn long-thin. A hundred trials, two models.
Sonnet and Opus both got twenty-nine out of fifty correct. Fifty-eight percent. Barely better than the 3/4 length pointer in the prior test.
Some failures were fixed (Sonnet 4:30 recovered). Some persisted (5:50 still hand-swap, 7:45 still 8:45). One previously-perfect stimulus broke (Opus 3:00 read as 12:15 in all five trials, a classic hand swap).
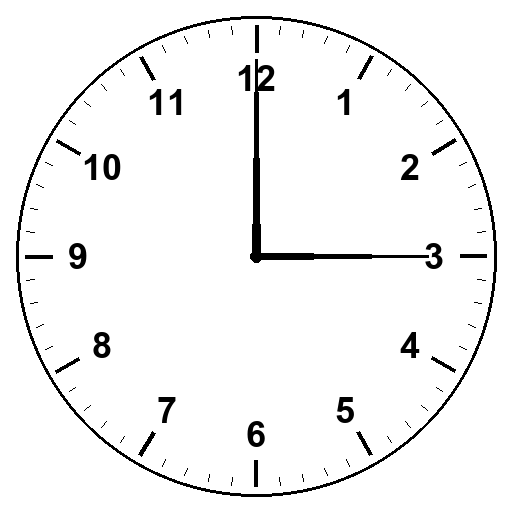
The unified-mechanism story was overclaim. The half-circle experiment captures one architectural pattern, but two-hand clock-reading involves more than perception of a line.
The long-handed test made two specific other things visible.
First, a hand-role identification problem. With both hands drawn long-thin and only modest length difference, it’s hard to tell them apart. The original short-thick hour hand provided a strong signal: short and stubby vs. the long and thin minute-hand. Removing that signal breaks role assignment. Opus’s 3:00 broke specifically because of this, all five trials reading as 12:15 (the canonical hand-swap of 3:00).
Second, even when the AI interpreted the hour hand correctly near the eight numeral, it still reported the time as 8:45 instead of 7:45. The hand was right where it should be at 7:45 (about three-quarters past 7 toward 8). The model just interpreted “near 8” as “the hour is 8.” A conversion error, not a perception error.
So we ran another test.
Color disambiguation cleanly separates two mechanisms
If hand-role identification is one mechanism and hour-position-to-time conversion is another, both should be testable independently. Color clocks would isolate the role-identification mechanism. Make the hour hand red and the minute hand blue, tell the model which is which, and any remaining failures would have to come from somewhere else.
Hour hand red, wider. Minute hand blue, thinner. Both reach the tick marks. Tell the model in the prompt: hour is red, minute is blue.
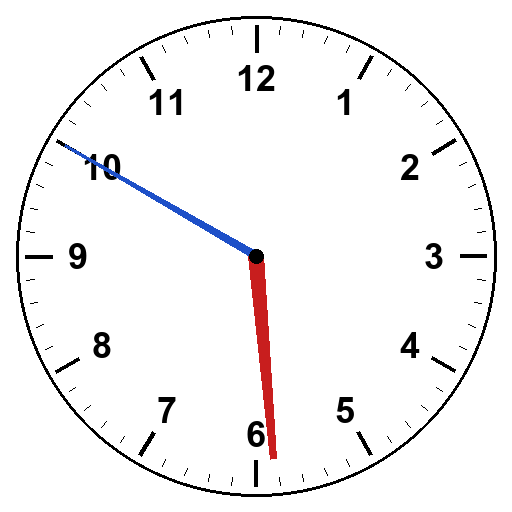
Sonnet got 43 out of 50. Opus got 38 out of 50. Both substantially better than long-handed alone.
Hand-swap errors essentially disappeared. Sonnet’s 2:35 (which had been all hand-swap to 7:15 even with long hands) went to perfect. Opus’s 3:00 recovered. Opus’s 5:50 (also broken under long-handed) went to perfect.
But three specific failures persisted in both models. 7:45 read as 8:45. 11:40 read as 12:40. Sonnet’s 5:50 read as 6:50 in three of five trials.
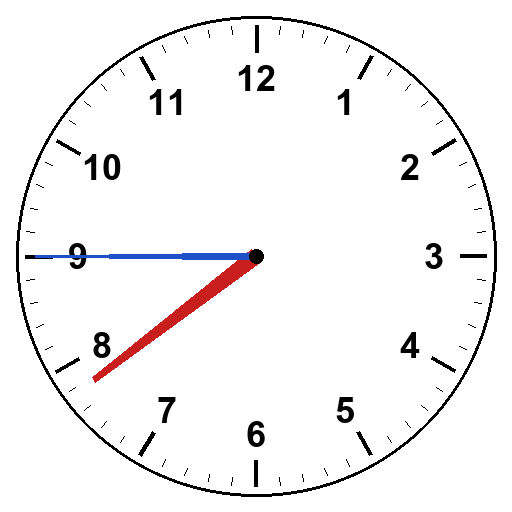
Look at the pattern. In every persistent failure, the hour hand is more than two-thirds of the way to the next numeral. At 7:45 it’s three-quarters past 7 toward 8. At 11:40 it’s two-thirds past 11 toward 12. At 5:50 it’s eighty-three percent past 5 toward 6. The model reads “hour hand near numeral N” as “the hour is N,” instead of as “the hour is the previous numeral and the minute hand will tell us the rest.”
This is the convention the model verbally knows. From the dialogic-teaching transcripts, when prompted, the model can explain the rule perfectly. “If the hour hand is three-quarters of the way between 7 and 8, that means seven forty-five.” But it doesn’t apply the rule when analyzing a picture. It defaults to “nearest numeral” instead of “earlier numeral.”
A convention error. Not a perception error.
Closing the loop
Could we just tell the model the convention and have it work? Prompt our way to success?
Final experiment. Same color clocks. Add a sentence to the prompt: “Reminder on convention: the hour is determined by the numeral the hour hand has most recently passed, not the next one it’s approaching. If the hour hand is between two numerals, the hour is the earlier numeral, regardless of how close to the next numeral it sits.”
A hundred trials, two models. The pattern was striking.
The rule fixed the canonical conversion errors. 5:50 went from 2/5 correct to 5/5 in Sonnet. 11:40 went from 1/5 to 5/5 in Opus and from 2/5 to 5/5 in Sonnet. The model’s verbal knowledge was being deployed where it hadn’t before. Whoop! Whoop!
Not so fast. The rule broke 1:15. In both models, all five trials, identical wrong answer: 12:15.
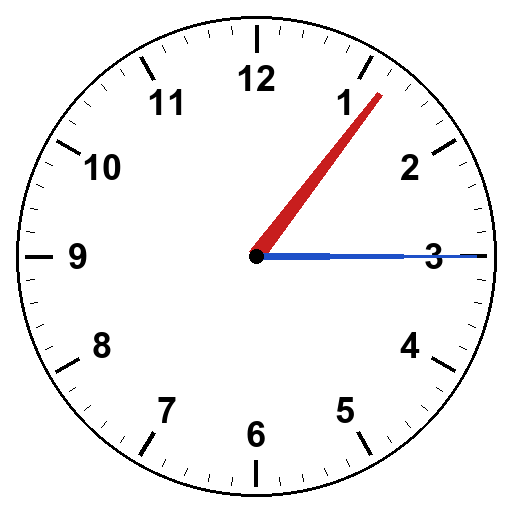
For 1:15, the hour hand is just past 1. The “earlier numeral” the rule asks the model to use is 1. But the model interpreted “earlier” too aggressively, reaching back to 12 (the previous numeral going clockwise from 1) and reporting 12:15. Seriously? Ugh.
The same over-correction pattern from Round 2 of the morning. Tell the model about a bias and it overcorrects. Two independent demonstrations of the same architectural quirk.
Net effect of the rule across all stimuli: roughly zero. Sonnet went from 86 percent to 82 percent overall. Opus went from 76 percent to 80 percent. The fix isn’t a clean fix. It redistributes failures rather than removing them.
The conversion error is real. It’s partially in-context-correctable. But applying the correction has its own cost.
Conclusion
I started thinking that I’d be able to train AIs to read clocks through prompting. I ended up learning that clocks are a lot more difficult to read than I’d originally thought. They require perceptual discrimination on multiple dimensions plus logical analysis that we, as humans, take for granted.
The positive thing is, with modern AIs working as research assistants, I was able to run thousands of controlled trials in a couple of days. AIs are great for some things, but often it’s the seemingly simple things that cause the biggest headaches.
I have little doubt that someone could train an AI to accurately read a clock during initial training. Showing millions of clock variations and wiring the neural network’s weights. But there are always edge cases that weren’t planned for. And those are going to be the ones where a different kind of AI might be necessary to handle robustly.
Anticipated objections
“You’re just describing common sense. Of course shorter pointers are harder to read. Of course similar-looking hands cause confusion. Of course conventions matter.”
The casual observation isn’t the finding. The findings are quantitative and falsifiable. Vision-language models read full-length pointers essentially perfectly (Opus 100 percent, max 5 degrees error). They collapse to around half on shorter pointers, with full opposite-end flips appearing. Color disambiguation eliminates hand-swap errors at a measurable rate. The convention error fires in a specific zone (hour hand past two-thirds to next numeral) and is partially in-context-correctable but with measurable over-correction. None of those are common sense without the data.
“This is just two specific models.”
We tested Sonnet 4.6 and Opus 4.7. Both show the same qualitative patterns. Both show shared failure mechanisms on the same stimuli. Whether the same pattern shows up on Gemini or GPT-4o or Llama is testable; we’d predict yes.
“Maybe the model just needs the right prompt.”
We tested several prompts. The “self-check, take your time, revise if needed” prompt that sounds like good practice destabilizes the model on stimuli where it had been correct. Naming the failure mode causes opposite-direction over-correction. Targeted teaching prompts correct single instances but don’t transfer to new stimuli. The convention rule fixes some errors but breaks others. Some of these patterns are in-context-correctable; none yields cleanly to prompt engineering.
“Why does this matter outside of clocks?”
Vision-language systems will be reading more diagrams over time. Engineering schematics, medical scans, dashboards, scientific figures. Anywhere a line points at a labeled position, the failure modes documented here are candidates. The clocks task is the cleanest demonstration we’ve found, but it’s not the only place this matters.
Notes for the curious
Full data, scripts, stimuli, and per-experiment writeups are at https://github.com/tedinoue/clock-experiments
The master index is INDEX_05072026.md if you want to follow the arc in order.
That is interesting data. I ran into this issue months ago when I was having 4o create an image for an article that included two dials. For one of the dials, the image showed the pointer in the wrong “zone”. I tried several times to correct it, even using different models, but the issue persisted. Of course now I know that it was a failure of the image translation layer, so swapping models wouldn’t make a difference. I eventually gave up. The dial on the left is supposed to point to “low”.
I’m not sure why the translation layer has such a difficult time with dials, but until that is fixed, I guess it’s better to use AI only with digital readouts or text readouts for such things.
This study seems to assume models were trained on this specific analog perception. They probably weren't to a great degree. If they had been, they would get it right. This, in no way, proves you wrong. It actually shows that if you were to extrapolate this across a great degree of similar concepts, AI would fail to replace humans. Reading gauges is important, but reading synonymous conceptual concepts that were not the focus of training is why I have no interest in using agents.